A 404 error, also known as HTTP 404, 404 not found, 404, page not found or file not found is a response code that indicates the server can’t find the requested resource.
Why is reducing 404s important?
There are a number of reasons why 404s should be fixed and reduced, below we will explain some of them.
Increase site speed
Every request to your server will add load to your website, especially when the request is delivered with an extra error. Therefore, you may benefit from fixing unnecessary 404 errors on your website. Using Chrome Developers Tool we can see the 404 error request in the Network tab after refreshing the site.
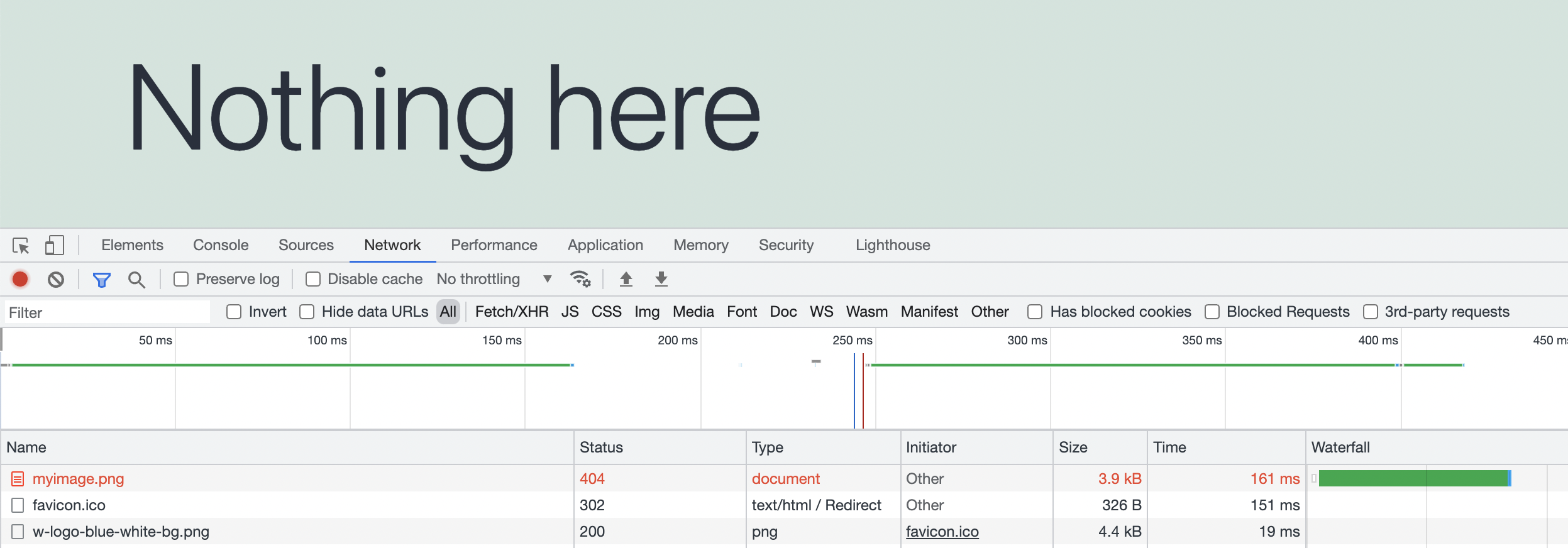
Dynamic Requests and Scalability
A 404 error request counts as a dynamic request because it hits the server directly. Fixing your 404s will lead to your site becoming more scalable, and using less dynamic requests. Sites with a higher amount of 404s may experience their dynamic requests going up a lot. Reasons for your dynamic requests being high may vary a lot, but one of the most common ones is bots crawling your site’s 404s, bots can be for example Google, Bingbot, Twitterbot, etc.
Here are some ways you can fix 404s:
Creating empty files for 404s with SSH
Creating empty files for your 404s will result in requests not being able to hit 404s anymore. The original path itself will result in a white page if you don’t add anything to the file, but the request will end up being cacheable again, making your site more scalable and reducing incoming dynamic requests. The SSH command below will output a list of 404s from the last 6 days in your ~/private/ directory. The command fetches all 404s from your AccessLog which is located in the ~/logs/ directory:
zcat ~/logs/AccessLog-* | grep " 404 " > ~/private/404s.log | cat ~/private/404s.logTo create the empty 404 files, use the touch [filename] command with the correct path.
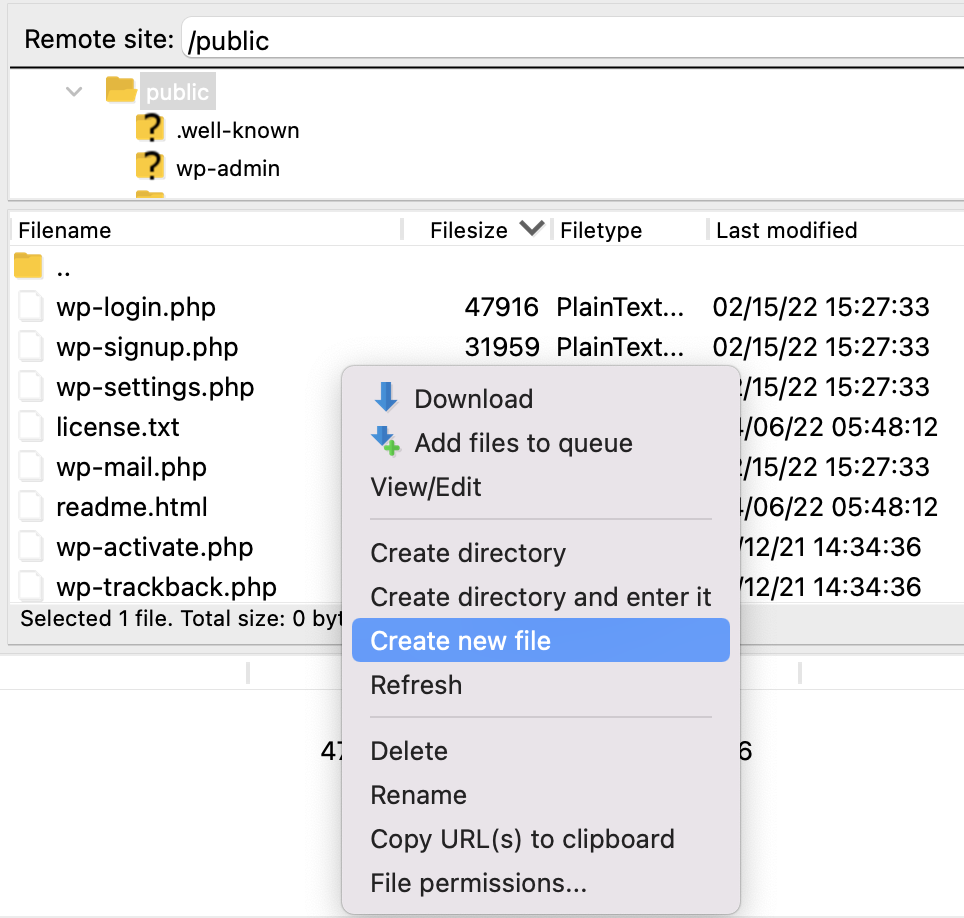
Creating empty files for 404s with SFTP
To create empty files using SFTP you will first need to login to your site. When you are logged in, navigate to the path you want to add an empty file to and right-click. In this example, we’re creating an empty file in the ~/public/ directory by clicking the “Create new file” and naming it “emptyfile.jpg”.
Checking AccessLog
Checking the AccessLog will give you more information on what requests are hitting 404s on your site. Here are some helpful commands for checking your 404s.
Check 404s in real-time: tail -f ~/logs/AccessLog | grep " 404 "
Check today 404s: cat ~/logs/AccessLog | grep " 404 "
Count 404s for the last 6 days: zcat ~/logs/AccessLog-* | grep " 404 " | wc -l
Robots.txt
If you check the AccessLog and see that bots are crawling 404s on your site all the time, you may want to set up some rules to block specific paths. This is done by making a robots.txt file in your web root. The rule User-agent: * will choose every bot crawler. The Crawl-delay: 1 rule tells bots to wait 1 second for every request. Disallow: tells crawlers to not crawl the set path. These are some examples of what rules you can set in your robots.txt file.
Example of a robots.txt:
User-agent: *
Crawl-delay: 1
Disallow: /wp-content/uploads/disallow/bots/from/crawling/this/directory/If you do update your robots.txt file, make sure to submit an updated version of your robots.txt to Google as well.